Seoses Datacamp’i kursuse Topic Modeling in R läbi tegemisega tekkis soov õpitut ka praktikas rakendada. Antud kursus annab kiire ülevaate, kuidas topic modelling (eesti keeles: teemade modelleerimine) metoodikaid kasutades tuvastada tekstides esinevaid teemasid.
Analüüsiks sobivaks tekstiks valisin Eesti kirjandusklassika Tõde ja Õigus osad I-V. Tekstid on kättesaadavad täismahus Vikitekstide lehelt. Analüüsi käigus ajasin kõigi 5 osa peatükid piltlikult omavahel sassi ja kaotasid viite, mis raamatust mingi peatükk pärineb. Eesmärgiks oli proovida kasutada topic modelling metoodikat selleks, et tuvastada teksti põhjal, millised peatükid kuuluvad ühte teemasse (ühte raamatusse). Lisaks Datacamp’i kursusele oli analüüsi tegemisel palju abi ka raamatu Text Mining with R peatükist Topic modeling.
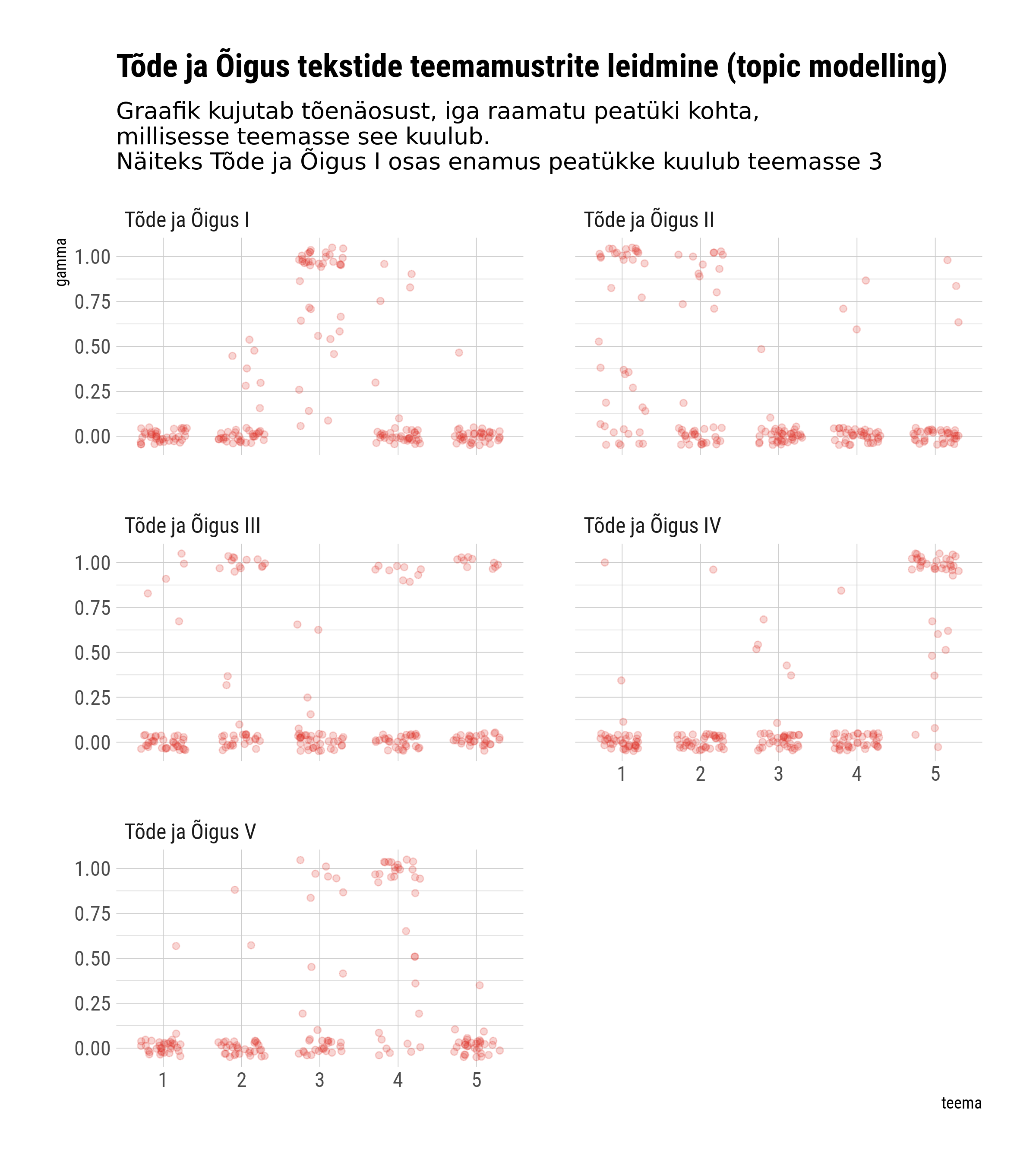
Alloleval graafikul on kujutatud iga raamatu peatüki kohta, millise tõenäosusega kuulub see ühte viiest teemast. Enamuse raamatute puhul tuleb välja üks teema, millisse suurem osa peatükke paigutub. Kõige segasem tundub olukord olema III osaga, mille peatükid jagunevad suhteliselt võrdselt kolme teema vahel. Kõige paremini on mudel tuvastanud teemade põhjal aga I ja IV osa.
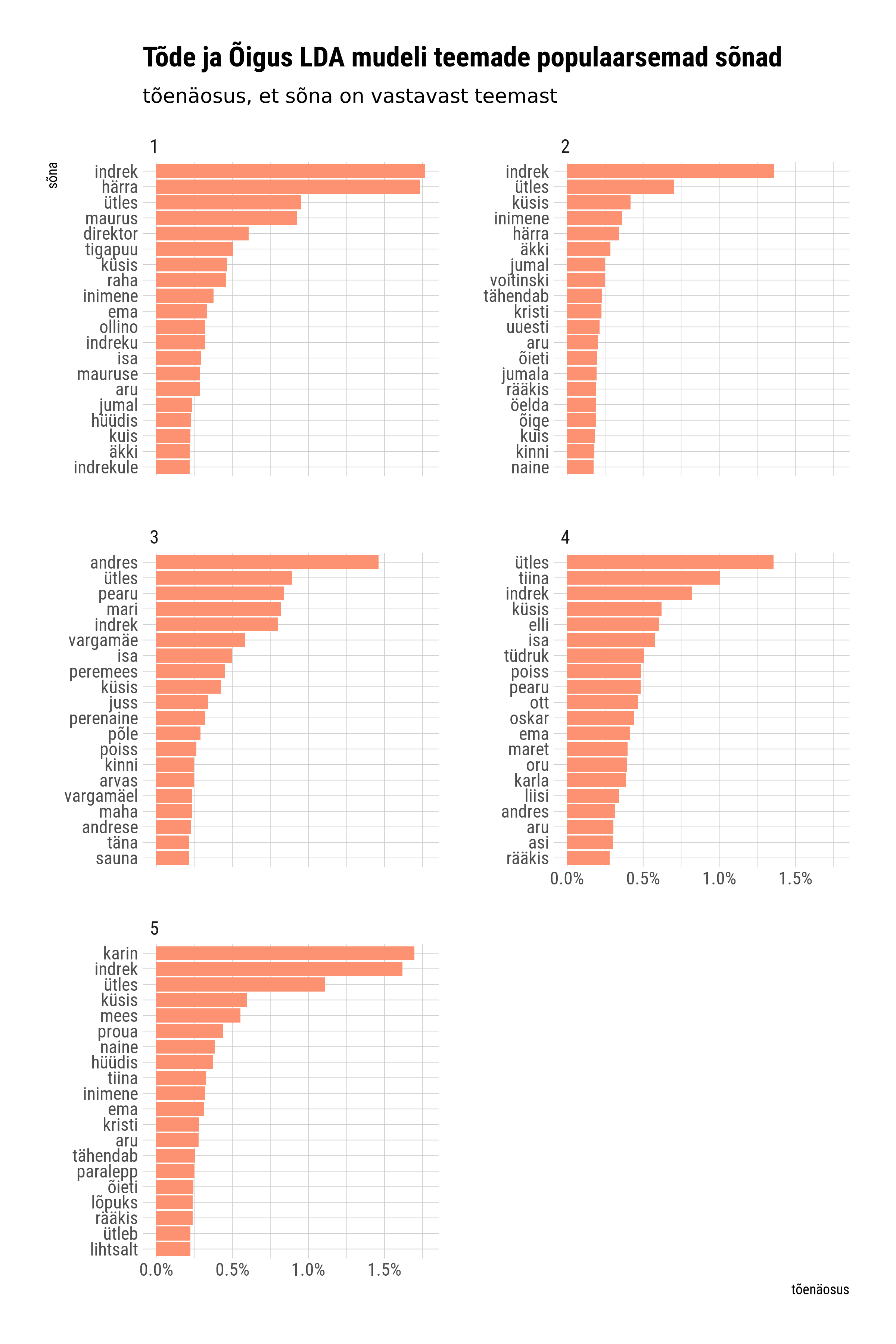
Järgmisel graafikul on kujutatud iga tuvastatud teema kohta kõige iseloomulikumad sõnad. Näiteks teema 1 puhul paistavad välja mitmed sõnad, mis viitavad Indreku kooliaastatele. Just seda kajastab Tõda ja Õigus II osa, mille enamus peatükke ka 1 teema alla klassifitseerusid. Teema nr 3 iseloomulikud sõnad nagu Vargamäe, Pearu, Juss, Mari jne. viitavad raamatu I osale, mille enamus peatükid klassifitseeruvad just selle teema alla.
Kuidas?
Andmete allalaadimise, puhastamise ja modelleerimise skript on leitav Githubist: https://github.com/toomase/tode_ja_oigus.