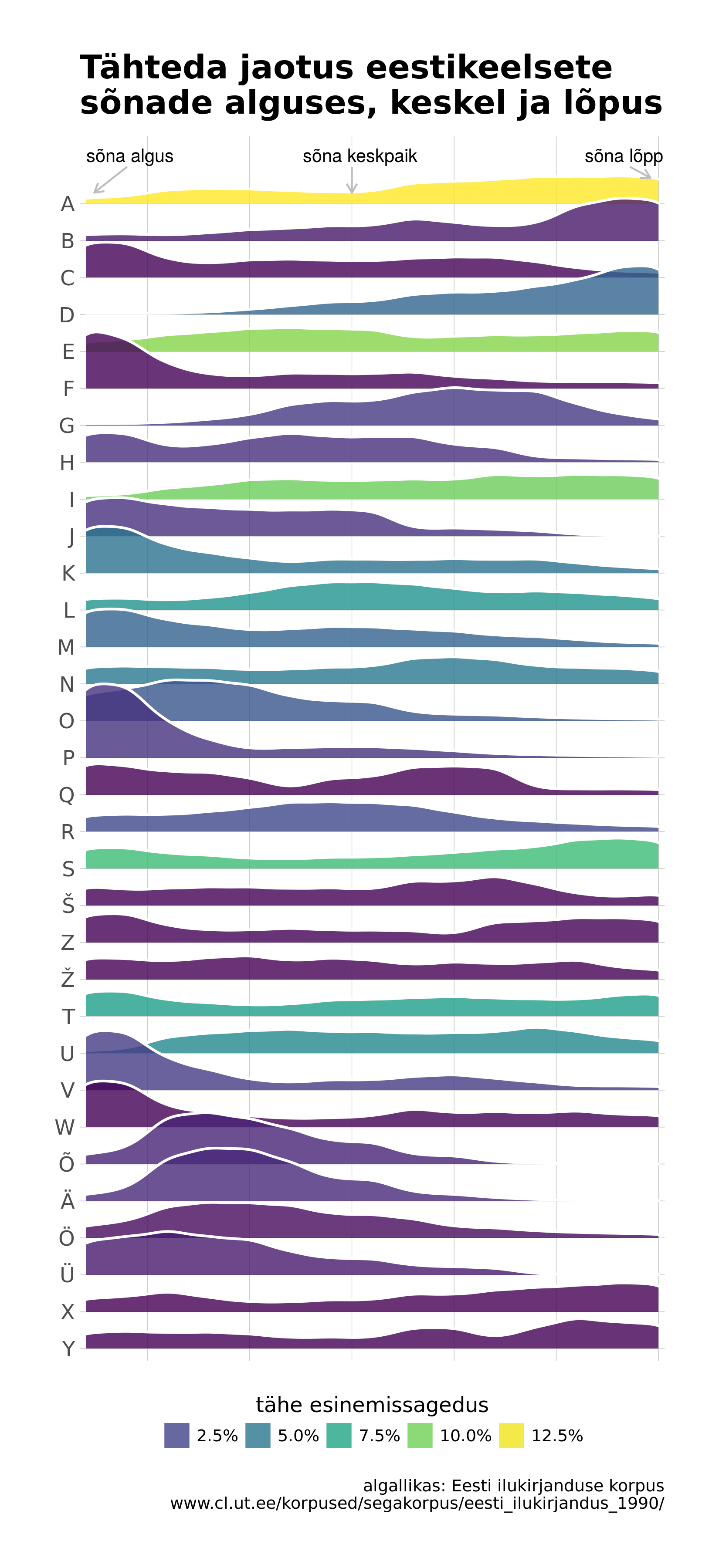
Otustsasin teha veel ühe postituse, kus esikohal on uus ja huvitav graafikutüüp joyplot. Kasutan seda, et visualiseerida tähtede jaotust eestikeelsetes sõnades. Eesmärgiks on näidata iga tähe kohta, kas see esineb eesti keeles rohkem sõna alguses, keskpaigas või lõpus.
Andmeallikana kasutan eesti keele ilukirjanduse korpusest random 1 miljonit sõna. Igas sõnas tuvastan kõigi tähtede suhtelise asukoha ning summeritud tulemusest tulebki kokku joyplot. Inspiratsiooni sain blogipostitusest Graphing the distribution of English letters towards the beginning, middle or end of words.
Allolevalt graafikult on näha, et näiteks P-täht esineb eesti keeles enamasti sõna alguses, D-täht pigem sõna lõpus ja kõige populaarsem, A-täht, on jaotunud ühtlasemalt, aga on enam levinud sõnade teises pooles.
Kuidas?
Lühidalt kirjeldasin metoodikat juba postituse alguses, aga täpsemalt saab andmeanalüüsi detailidega tutvuda githubis.